A lot has changed since I finished my recursive homelab build two years ago. While an excellent learning experience, using Windows Server as the hypervisor and ZFS inside of a VM was the wrong choice. The reasons behind this statement are many and can very well be an entire write-up on its own. I have now switched to using Linux as the hypervisor with Windows as one of the VMs using the GPU via PCI passthrough. As far as the physical storage layout goes not a whole lot has changed. I have changed caching strategies a few times as I've learned how to better tune ZFS for my various workloads, otherwise the only real change is the addition of more physical disks.
ZFS is a powerful, complicated file system. Over time I found that you really need to tune it to your workload in order to keep performance relatively high. The main reason for why I chose ZFS is its superior claims to resiliency among other things:
Since I'm using ZFS this is easy to describe as it is very much a JBOD.
There are 12 SATA III spinning disks that sit inside the Norco enclosure. Not every disk is of the same capacity but they are all Western Digital's. None of the disks use SMR which I explicitly made sure of when I was building this out. The only disks that use SMR are a couple of spares that I use for cold storage backups.
The various NAND flash disks are a bit more mixed. There are two HP 2TB PCIe 3.0 NVMe drives, two Kingston 240GB SATA III drives, and three Crucial SATA III drives. All of these drives live either on the motherboard (NVMes) or somewhere in the case.
I use my server for many things, usually in parallel and for multiple people connecting from different places:
There are two pools, one backed by the NVMe drives and another backed by the SATA HDDs/SSDs.
This is where the host and all of the VM block devices live. The only exception to this is the block device that attaches to the Windows VM as it is far too big to fit into this pool.
pool: rpool
state: ONLINE
scan: scrub repaired 0B in 00:17:25 with 0 errors on Sun Oct 9 00:41:26 2022
config:
NAME STATE READ WRITE CKSUM
rpool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
nvme-HP_SSD_EX950_2TB_xxxxxxxxxxxxxxx-part3 ONLINE 0 0 0
nvme-HP_SSD_EX950_2TB_xxxxxxxxxxxxxxx-part3 ONLINE 0 0 0
errors: No known data errors
This is where everything else lives.
pool: vault
state: ONLINE
scan: scrub repaired 0B in 11:26:36 with 0 errors on Sun Oct 9 11:50:38 2022
config:
NAME STATE READ WRITE CKSUM
vault ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
wwn-0xxxxxxxxxxxxxxxxx ONLINE 0 0 0
wwn-0xxxxxxxxxxxxxxxxx ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
wwn-0xxxxxxxxxxxxxxxxx ONLINE 0 0 0
wwn-0xxxxxxxxxxxxxxxxx ONLINE 0 0 0
mirror-2 ONLINE 0 0 0
wwn-0xxxxxxxxxxxxxxxxx ONLINE 0 0 0
wwn-0xxxxxxxxxxxxxxxxx ONLINE 0 0 0
mirror-3 ONLINE 0 0 0
wwn-0xxxxxxxxxxxxxxxxx ONLINE 0 0 0
wwn-0xxxxxxxxxxxxxxxxx ONLINE 0 0 0
mirror-4 ONLINE 0 0 0
wwn-0xxxxxxxxxxxxxxxxx ONLINE 0 0 0
wwn-0xxxxxxxxxxxxxxxxx ONLINE 0 0 0
mirror-6 ONLINE 0 0 0
wwn-0xxxxxxxxxxxxxxxxx ONLINE 0 0 0
wwn-0xxxxxxxxxxxxxxxxx ONLINE 0 0 0
special
mirror-5 ONLINE 0 0 0
ata-KINGSTON_SA400S37240G_xxxxxxxxxxxxxxxx ONLINE 0 0 0
ata-KINGSTON_SA400S37240G_xxxxxxxxxxxxxxxx ONLINE 0 0 0
cache
ata-Crucial_CT1050MX300SSD1_xxxxxxxxxxxx ONLINE 0 0 0
ata-Crucial_CT750MX300SSD1_xxxxxxxxxxxx ONLINE 0 0 0
ata-Crucial_CT750MX300SSD1_xxxxxxxxxxxx ONLINE 0 0 0
errors: No known data errors
There are a few major factors that contribute to improving performance across the board:
Additionally, the use of the correct ashift value for your pools is crucial. You can think of the ashift value as the exponent to the base of 2. Ashift is used for controlling the alignment shift and it should always match up to what your devices use. For example, many modern drives use 4k sector size. If your pool is filled with these drives then you'd want an ashift value of 12 as 2^12 = 4096. Some newer SSDs use an 8k sector size which would necessitate an ashift value of 13.
You'll notice one thing in common with the two pools above: they both make use of mirrored vdevs. Mirrored vdevs have a few advantages:
ZFS offers many ways to transparently compress your data, and since I do care about performance I opted to stick with LZ4. It is even the recommended algorithm. To give you an idea of the impact compression can make have a look at what it did for me for my block device that is used by the Windows VM for storing games:
NAME USED AVAIL REFER MOUNTPOINT
vault/vz/vm-104-disk-0 9.00T 40.7T 9.00T -
NAME PROPERTY VALUE SOURCE
vault/vz/vm-104-disk-0 compressratio 1.29x -
That is a 29% savings on the block device's original size of ~11.6TB.
All of the data on the NVMe-backed pool is backed up to the other pool on a nightly basis. Those backups along with most of the other data in the large pool is backed up to cold storage on a weekly basis using snapshots with ZFS replication. Backups make use of the same compression, record size, and block size settings from the source pools but are encrypted using AES-256 GCM.
After using ZFS for many years I can confidently recommend it. It has saved me more times than I can remember, and it provides an excellent foundation for whatever you're doing. The learning curve can be steep, and it can take some time to understand how to tune it to your workload. With some careful planning and light research you can quickly create a rock solid storage layer for your needs.
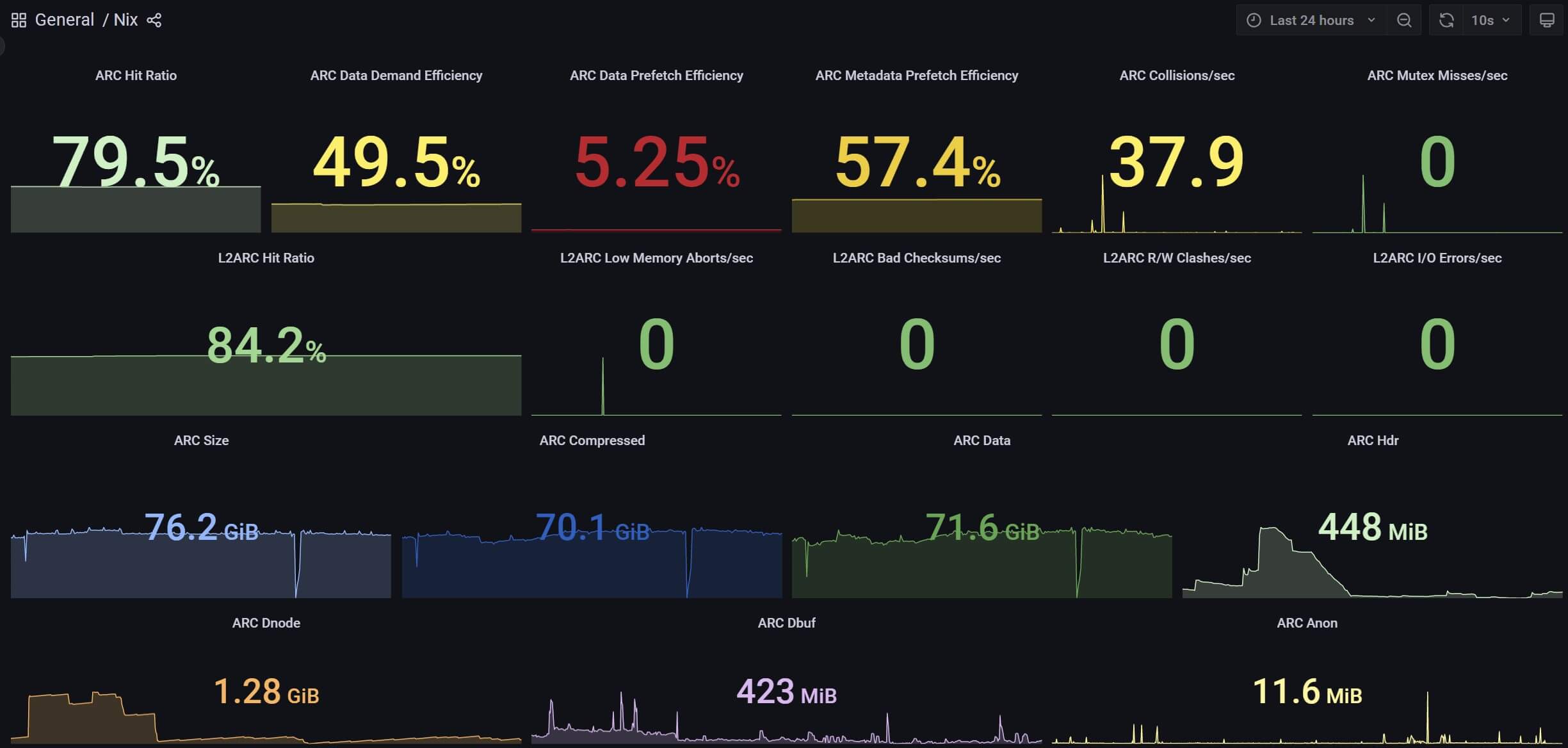
While things can greatly vary depending on your hardware, workload, and access patterns here's what you might expect to see if you use and tune ZFS in a similar way:

If you're interested to follow a setup like mine here is how you can achieve it.
I'm currently using Proxmox so I relied on their tooling to accomplish this.
zpool create -o ashift=12 POOL_NAME mirror DISK1_ID DISK2_ID mirror DISK3_ID DISK4_ID ... # use a different ashift if your devices aren't using 4k sectors
zfs set xattr=sa POOL_NAME # pool-wide
zfs set compression=on POOL_NAME # pool-wide, currently defaults to LZ4
zfs set recordsize=1M POOL_NAME/DATASET_NAME # for any datasets that primarily store files >= 1MB
zfs create -V SIZE -o volblocksize=1M POOL_NAME/VOL_NAME # for block devices that primarily store files >= 1MB
zpool add POOL_NAME cache DISK1_ID DISK2_ID ... # adds an L2ARC to the pool
zpool add POOL_NAME special mirror DISK1_ID DISK2_ID # adds a mirrored special vdev to the pool
zpool create -o ashift=12 -O encryption=aes-256-gcm -O keyformat=passphrase -O keylocation=prompt POOL_NAME DEVICE_NAME